



| Technical Name | 可擴增與模組化之AI硬體加速器 | ||
|---|---|---|---|
| Project Operator | National Chung Hsing University | ||
| Project Host | 吳崇賓 | ||
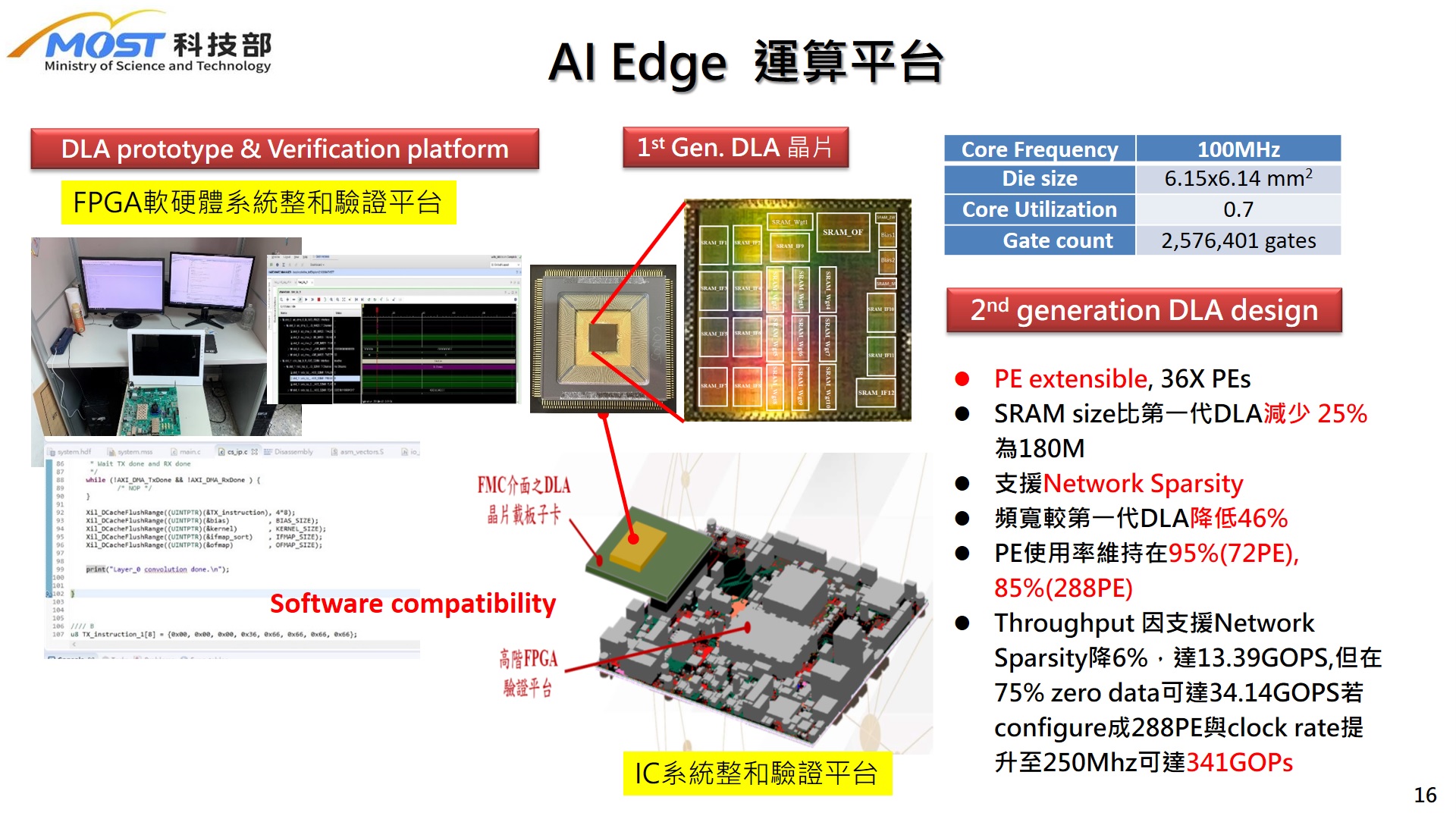
| Summary | "1. Use PE Cluster to make the calculation reconfigurable,can be modularized into 36X PEs, supporting up to 2160PEs 2. It can be configured as an independent IP with high computing throughputlow power consumption. The computing performance can reach 864 GOPS@200MHz when 2160PEs are employed." |
||
| Technical Film |
|
||
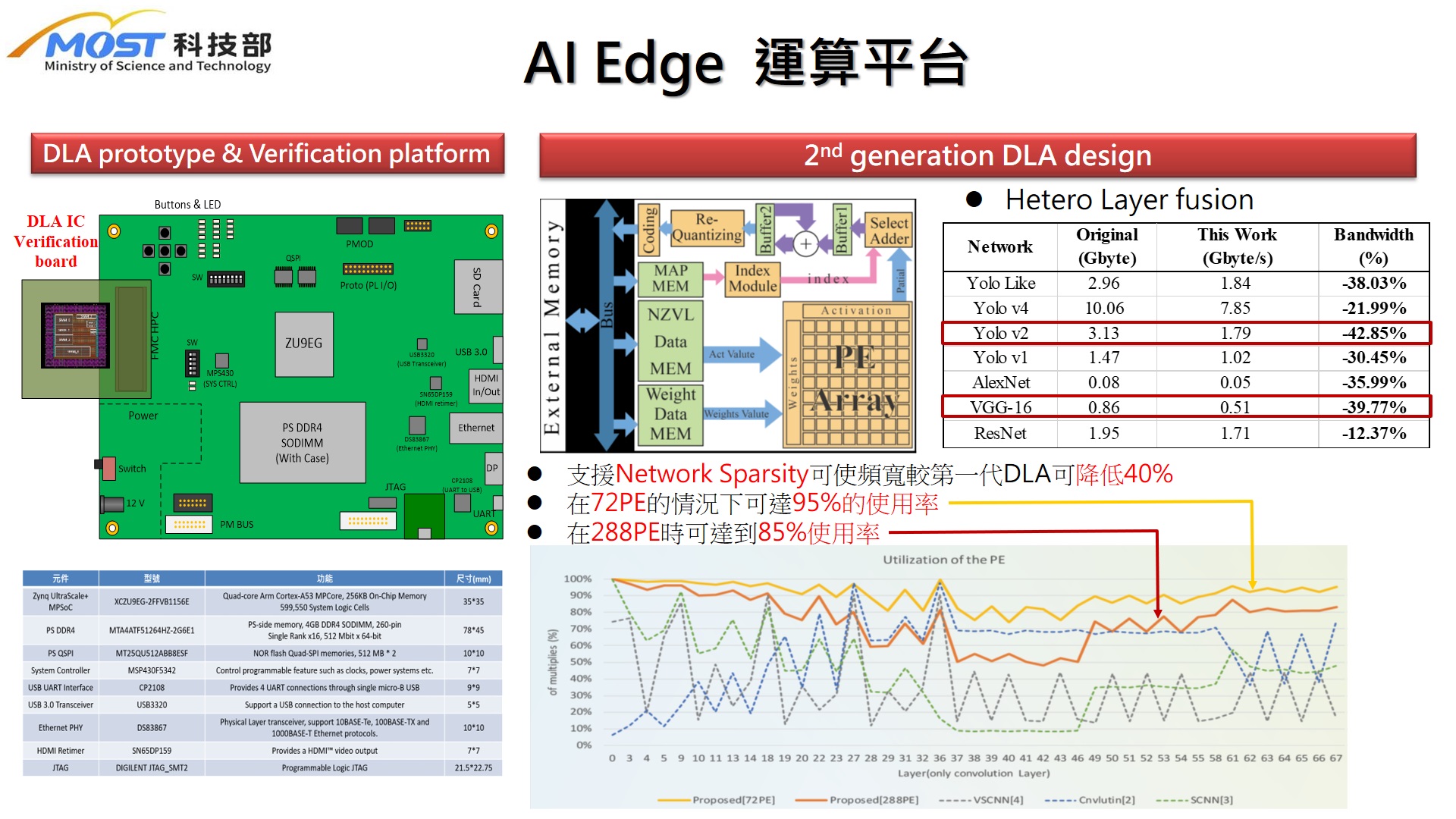
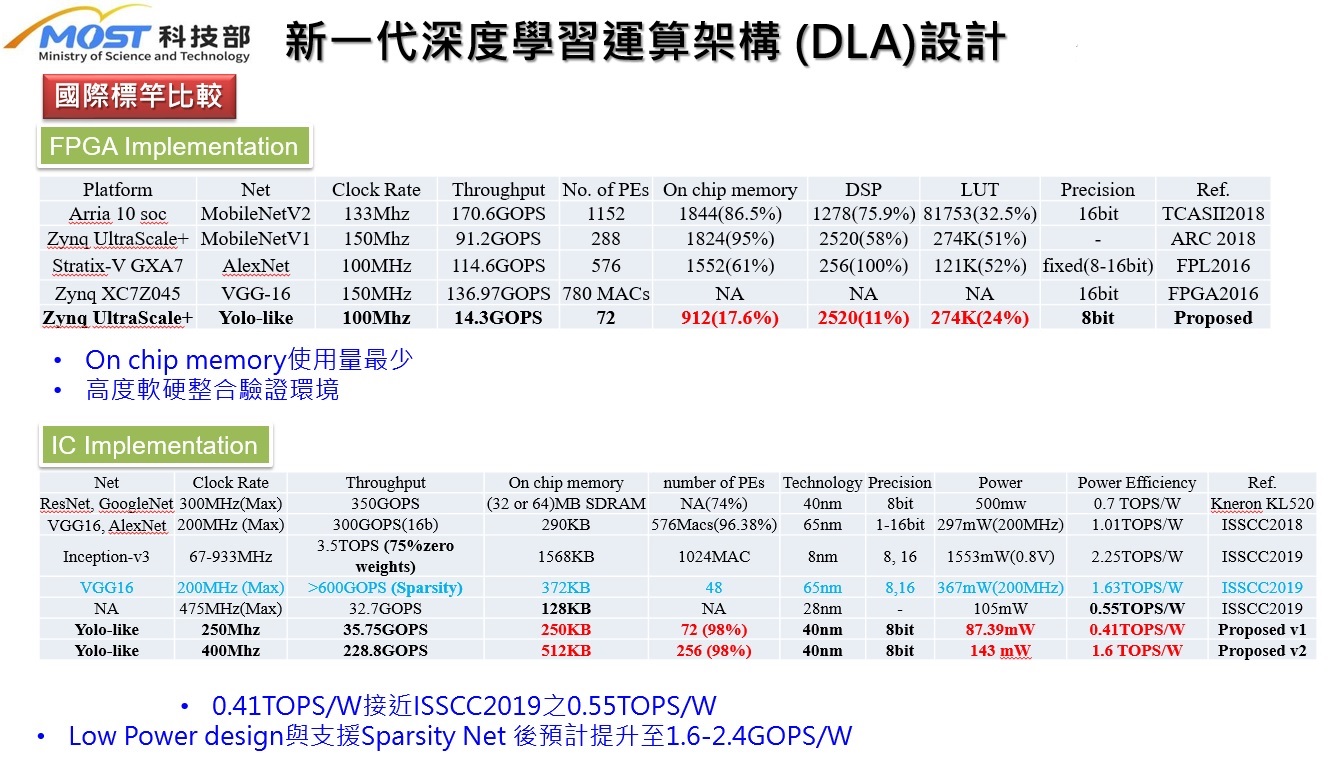
| Scientific Breakthrough | This technology adopts a PE Cluster based architecturethe design can be configured as an independent IP for either high performancelow power application. The design uses a modular 36-PE array as the building blockthe size can be extend to 2160PEs. Hetero Layer Fusion is employed to optimize the memory bandwidth. The computing performance can reach 864 GOPS@200MHz when 2160PEs are used. A minimum design of 36PEs can also obtain 3.58GOPs@50MHz. The utilization ratio of PEs is up to 98. The proposed architecture is fully verified in FPGA platformsIC HW/SW co-design systems. |
||
| Industrial Applicability | Due to the extremely high computational complexity, high-performance processors such as GPUs,FPGAseven ASICs are needed for AI applications. This approach is not viable for cost sensitive edge devices. The proposed AI accelerator IP design is both flexibleexpandable to meet various application requirements. It can be integrated seamlessly into an SoCthe design is fully verified in FPGA. Because of the expandable modular design, it can be adapted easily to another application subject to different design constraintsthe development time can be greatly shortened. |
||
| Matching Needs | 天使投資人、策略合作夥伴 |
||
| Keyword | Deep Learning Hardware Architecture Reconfigurable Hardware FPGA Implementation AI Accelerator Processing Element Acceleration Object Detection Convolutional Neural Network (CNN) Modularized Hardware IP Optimization | ||
- shuchi@dragon.nchu.edu.tw
other people also saw








