



| Technical Name | High-performance real-time speech enhancement system | ||
|---|---|---|---|
| Project Operator | Academia Sinica | ||
| Project Host | 曹昱 | ||
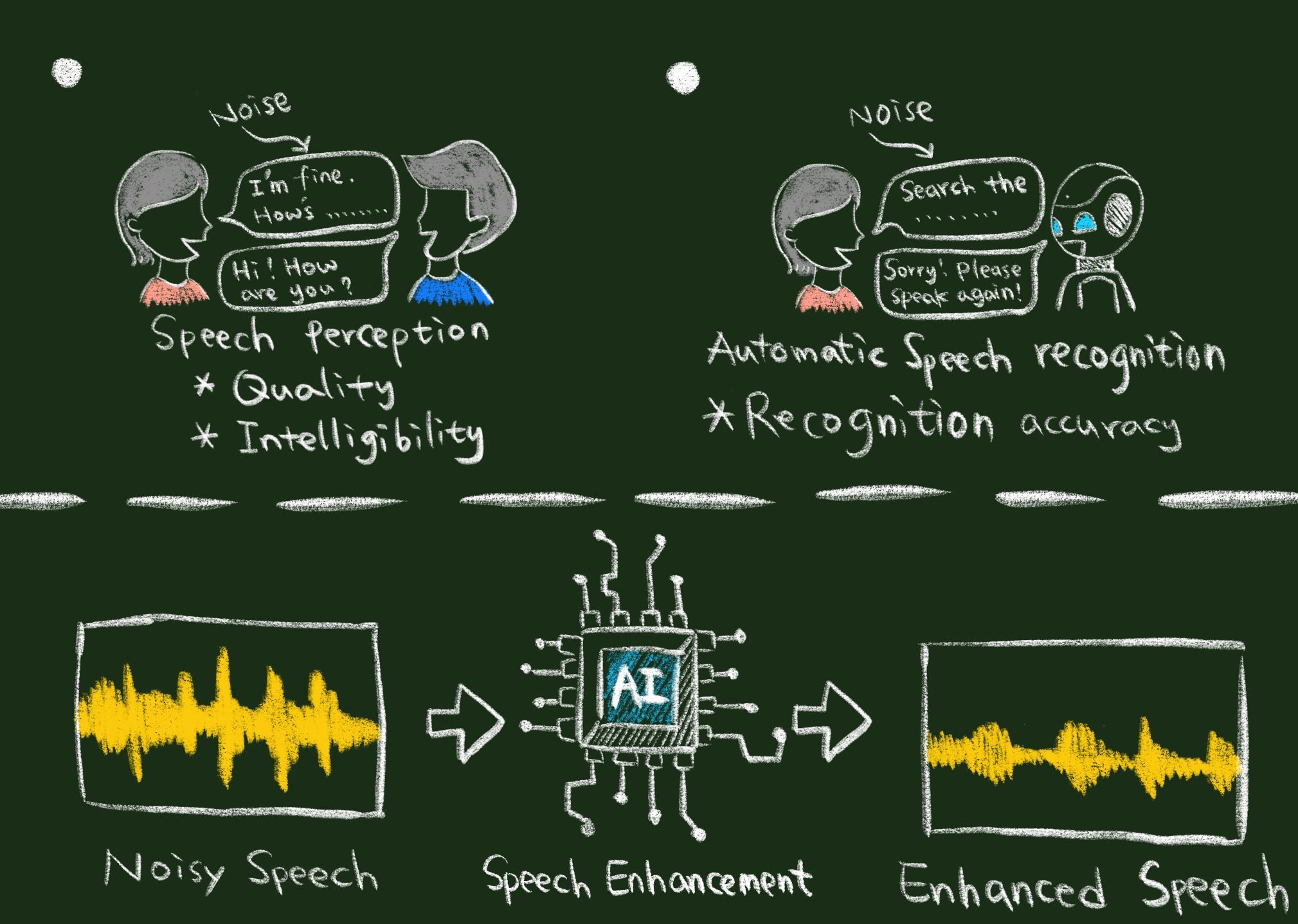
| Summary | Speech enhancement systems based on deep learning can more effectively represent the complex transformation from noisy speech to clean speech; they can also more accurately measure the parameters required to filter out the noise components in the noisy speech. When there is a sufficient amount of training corpus available, deep learning-based speech enhancement technology can provide more effective performance than traditional and other machine learning-based speech enhancement methods. Neural network-based models are the mainstream technology of deep learning methods and can automatically learn the statistical distribution behind the data. Generally speaking, deep neural networks (with multiple hidden layers) have better learning capabilities than shallow neural networks (with single or fewer hidden layers), because deep neural networks can learn more complex transformations. |
||
| Scientific Breakthrough | We propose novel speech enhancement (SE) algorithms with two focuses: (1) time-domain processing and (2) the adoption of an intelligibility-oriented objective function. The results show that the proposed approach provides a better performance than related studies in terms of computation efficiency, speech quality, and intelligibility. We also propose a generative adversarial network (GAN) based SE system that can simultaneously improve the speech quality and intelligibility of enhanced speech. We won a gold medal at the 5th World Invention Innovation Contest in 2019 and National Innovation Awards in 2018 and 2019 based on the derived SE models. |
||
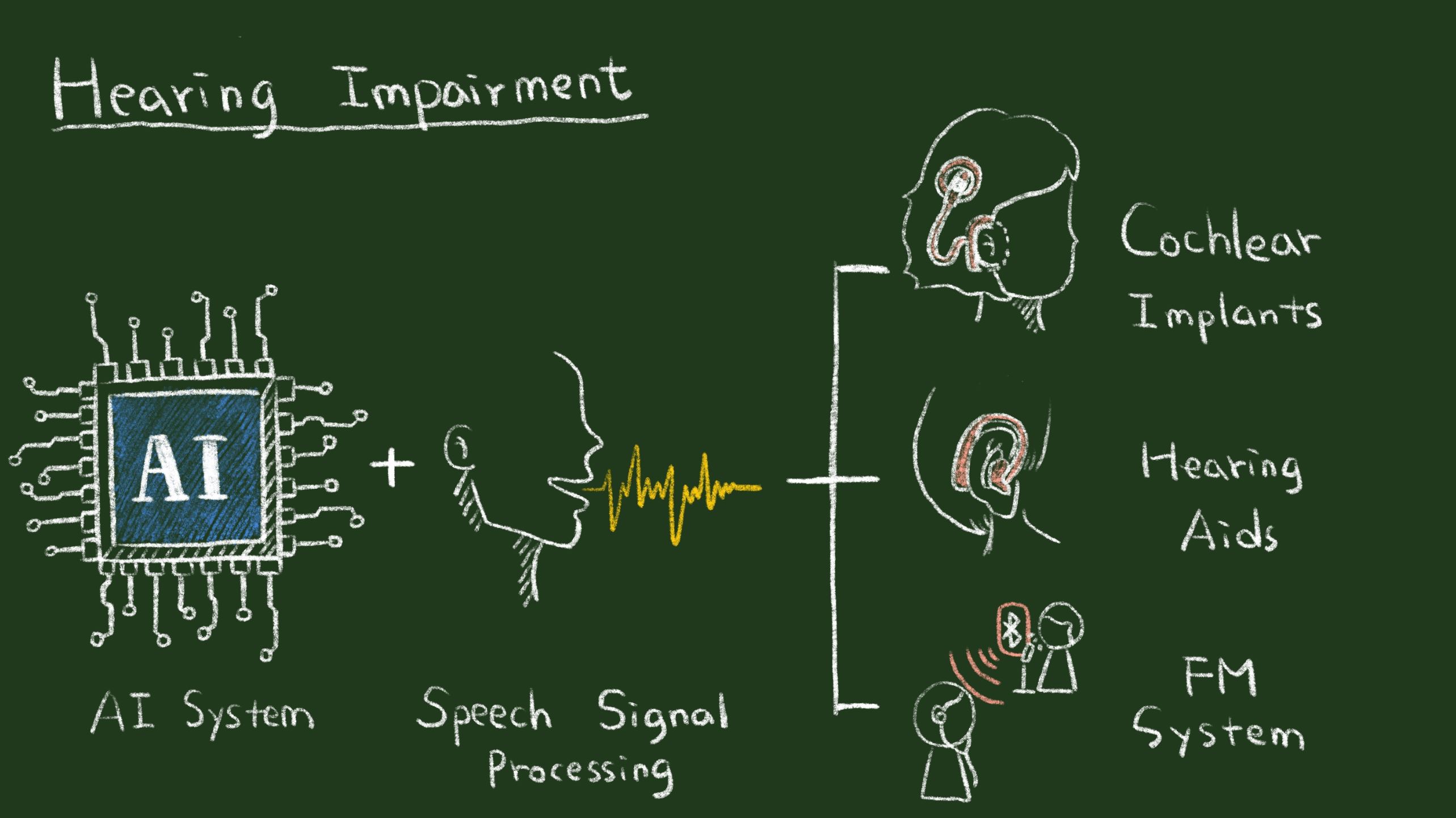
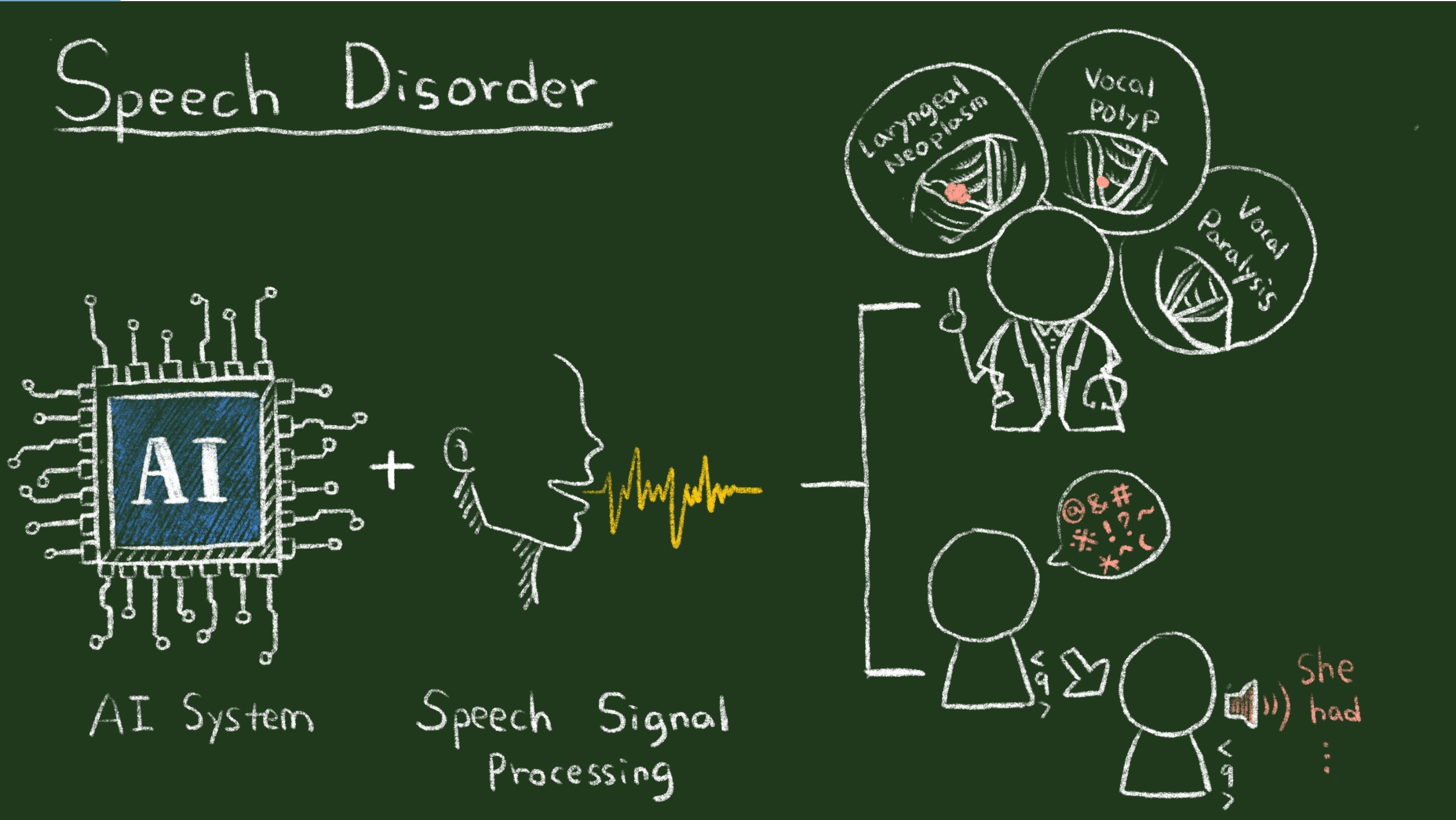
| Industrial Applicability | Nowadays, the growing percentage of the elderly and the inappropriate use of portable audio devices have led to a rapid increase in the population with hearing loss. Untreated hearing loss can cause feelings of loneliness and isolation in the elderly and may reduce learning ability of students. In the past few years, we are devoted to use advanced machine learning algorithms to derive high-performance speech enhancement (SE) systems. The derived SE systems can be applied to various assistive communication devices, hearing aids, and cochlear implants to benefit the speech communication of hearing/speaking impaired individuals, thereby improving their quality of life. Hopefully, the research outputs can promote the research and development in the related industry in Taiwan. |
||
| Keyword | speech enhancement deep learning speech intelligibility end-to-end time-domain speech enhancement assistive communication devices speech intelligibility speech recognition cochlea implants hearing aids FM system | ||
- yu.tsao@citi.sinica.edu.tw
other people also saw