



| 技術名稱 | 零資源之新語者語音合成技術 | ||
|---|---|---|---|
| 計畫單位 | 國立中央大學 | ||
| 計畫主持人 | 王家慶 | ||
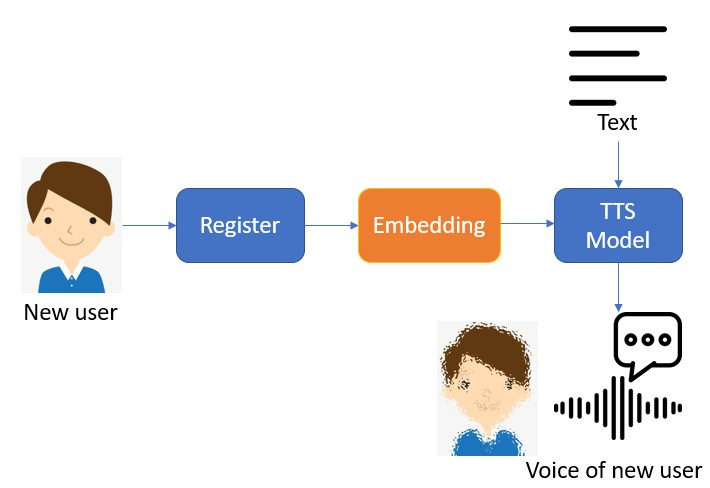
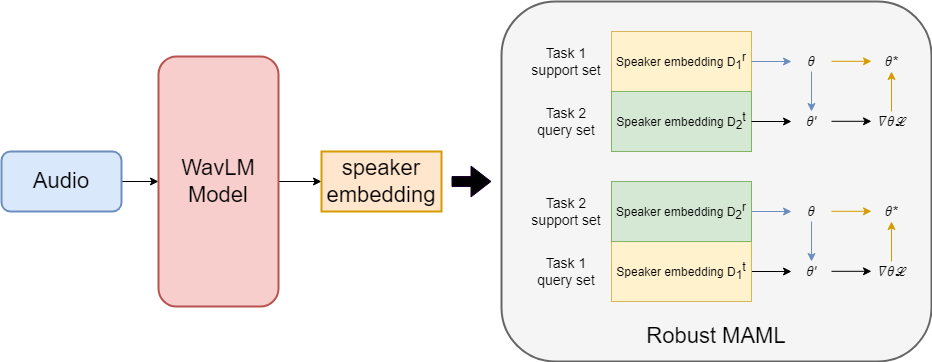
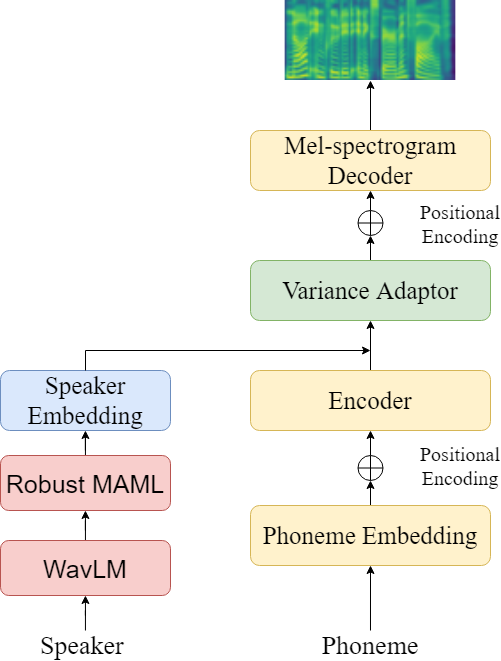
| 技術簡介 | 本技術使用了預訓練的語者編碼器來取得語音當中的語義資訊,及訓練了一個以WavLM為主體的語者編碼器,透過Robust MAML進行領域泛化的訓練方式來取得領域無關的語者資訊,使領域無關的語者資訊能夠適用在任何未註冊新語者上,並將此語者特徵的效果遷移學習至語音合成模型當中,進而達成零資源語音合成結果。 |
||
| 科學突破性 | 為了能夠擬合零資源未註冊語者在語音合成中的自然度跟相似度,我們使用Robust MAML的訓練方式取得領域泛化的語者特徵,使其能夠克服未註冊資料與註冊資料間領域差距的問題,有效地保留目標語者的領域無關語者特徵,並將此特徵使用於語音合成模型的訓練當中,改善原先模型中未註冊語者的自然度及相似度問題。 |
||
| 產業應用性 | 零資源語音合成系統的應用情境相當廣泛,根據不同的使用方式也能夠運用於各式各樣的情況下,如透過此技術,配音員在配音時只需要配音少量的語句,剩下的語句就能夠透過機器自己產生,亦或是透過此技術,也能夠創作出虛擬人物等。除此之外,根據語義編碼器的選擇不同,也能將技術運用於資料擴增、語音轉換等技術上。 |
||
| 關鍵字 | 語者編碼 領域泛化 元學習 語音合成 語音轉換 語音翻譯 資料擴增 遷移學習 前瞻語音技術 深度學習 | ||
- 聯絡人
- 王家慶
- 電子信箱
- jiacwang@gmail.com
其他人也看了