



| 技術名稱 | 基於人工智慧之語音增強系統 | ||
|---|---|---|---|
| 計畫單位 | 中央研究院 | ||
| 計畫主持人 | 曹昱 | ||
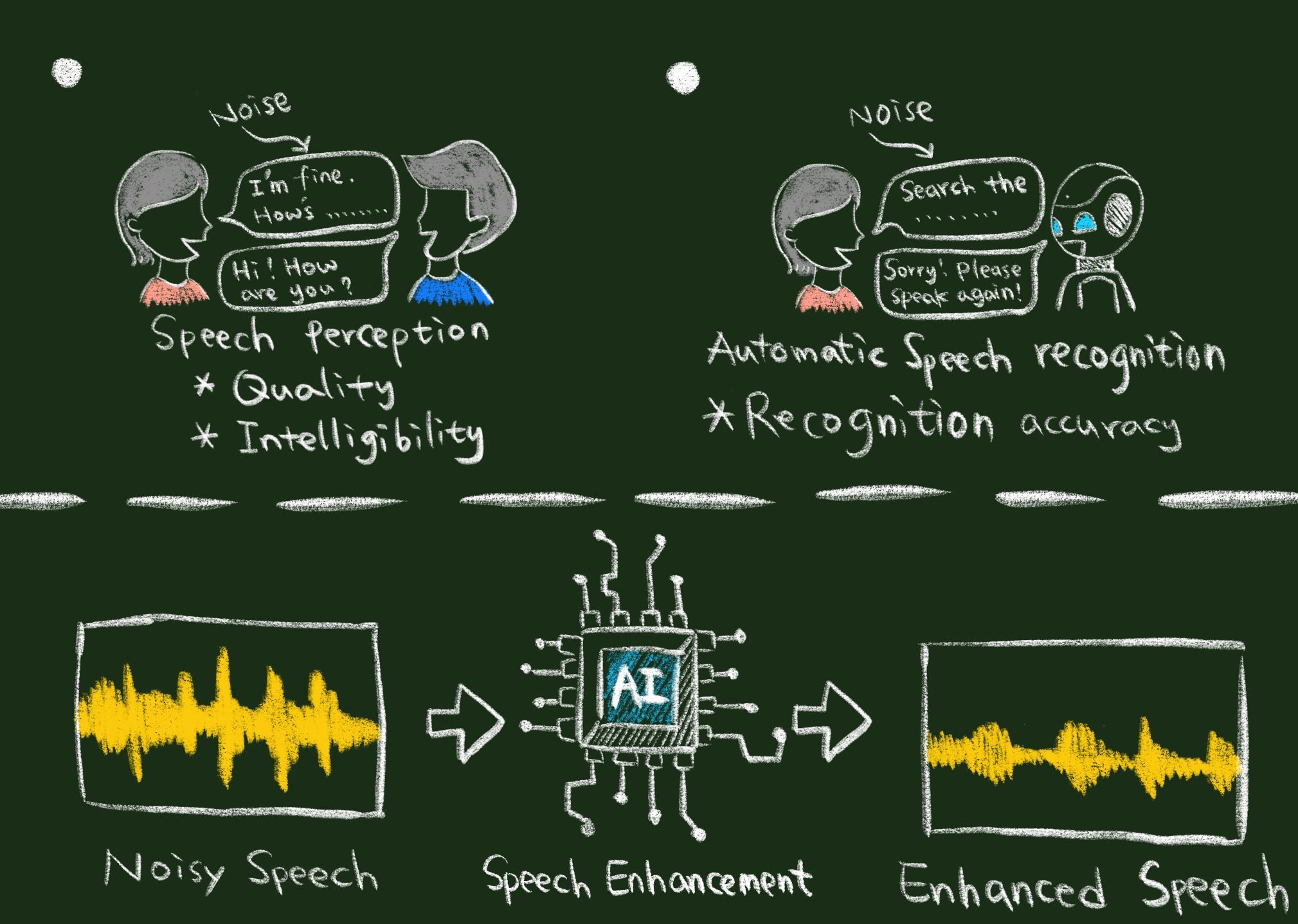
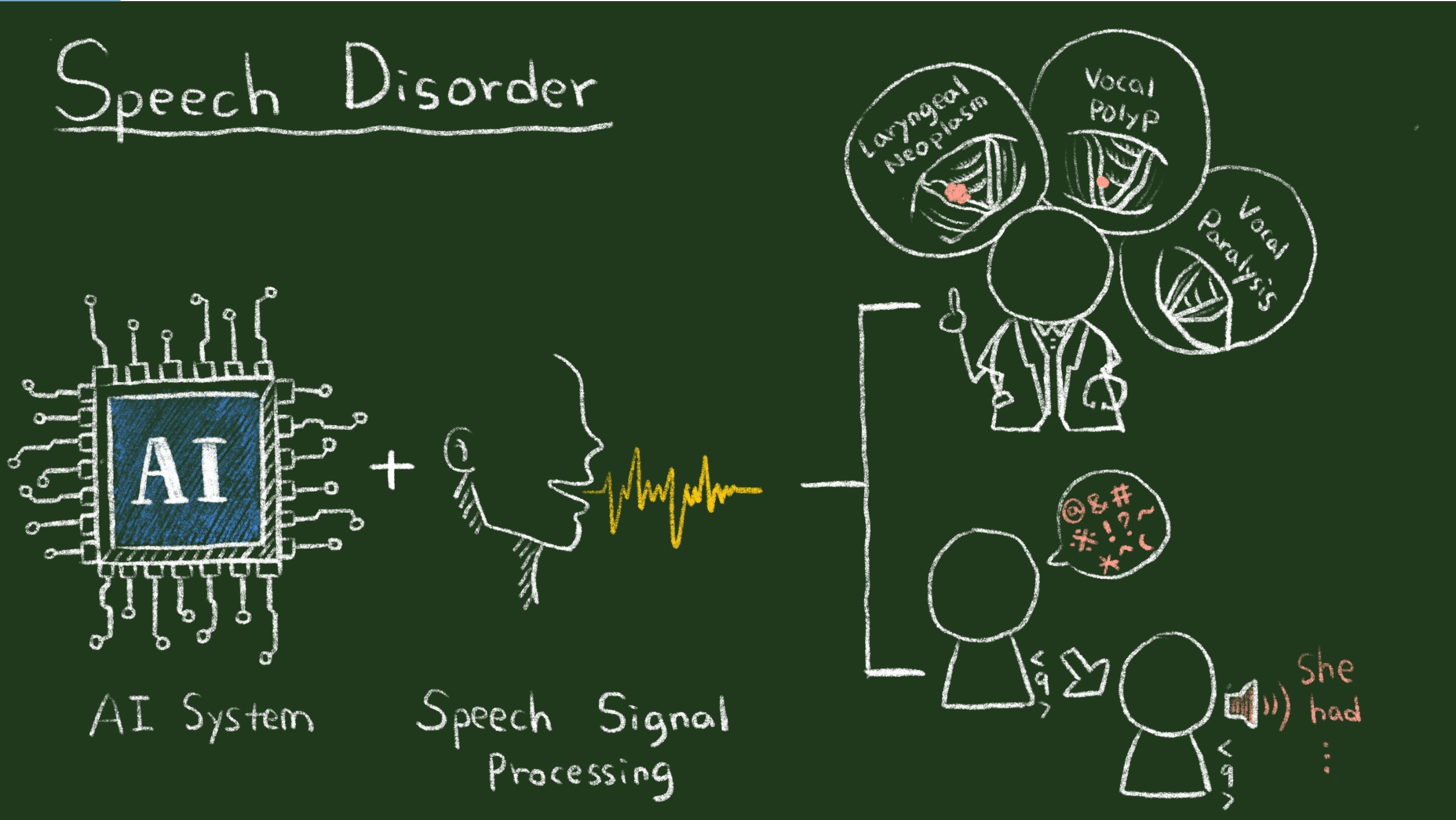
| 技術簡介 | 語音訊號是人與人、人與機器最自然、最便利的溝通介面。對人與人而言,我們可以基於語音訊號與其他人溝通、了解對方的情緒、身分、性別、甚至於生理狀況。對人與機器而言,我們可以利用語音當作輸入,直接對機器下達指令,或是查詢需要的資訊。近年來隨著科技的進步,有許多與語音相關的應用衍生出來,基於這些應用,人們可以更自由地透過語音與其他人或是機器溝通。然而在實際使用情況下,語音訊號很容易受到環境中的各種干擾影響,造成語音品質降低,進而影響使用者對於語音應用的感受。這些干擾源可概分為加成性噪聲,通道失真(例如由品質不佳的麥克風造成)和回音/混響(例如在浴室或隧道等不同的空間中產生的聲音現象)等。由於這些干擾通常同時出現,有效地消除語音中的干擾以得到乾淨語音訊號,進而提升語音訊號的品質以及理解度,是一項極具挑戰,但又是非常重要的任務,我們通常稱這個任務為語音增強。 |
||
| 科學突破性 | 我們提出基於深度學習理論的語音除噪演算法,有效提昇人與人、人與機器之間的溝通效率。我們特別針對強化理解力及語音品質的目標函數,研發端對端語音波形增強,並且整合深度及總體學習演算法及環境調適演算法,用來減輕在真實應用情境上可能遭遇到的訓練、測試環境不匹配問題,進一步提升語音除噪效能。 |
||
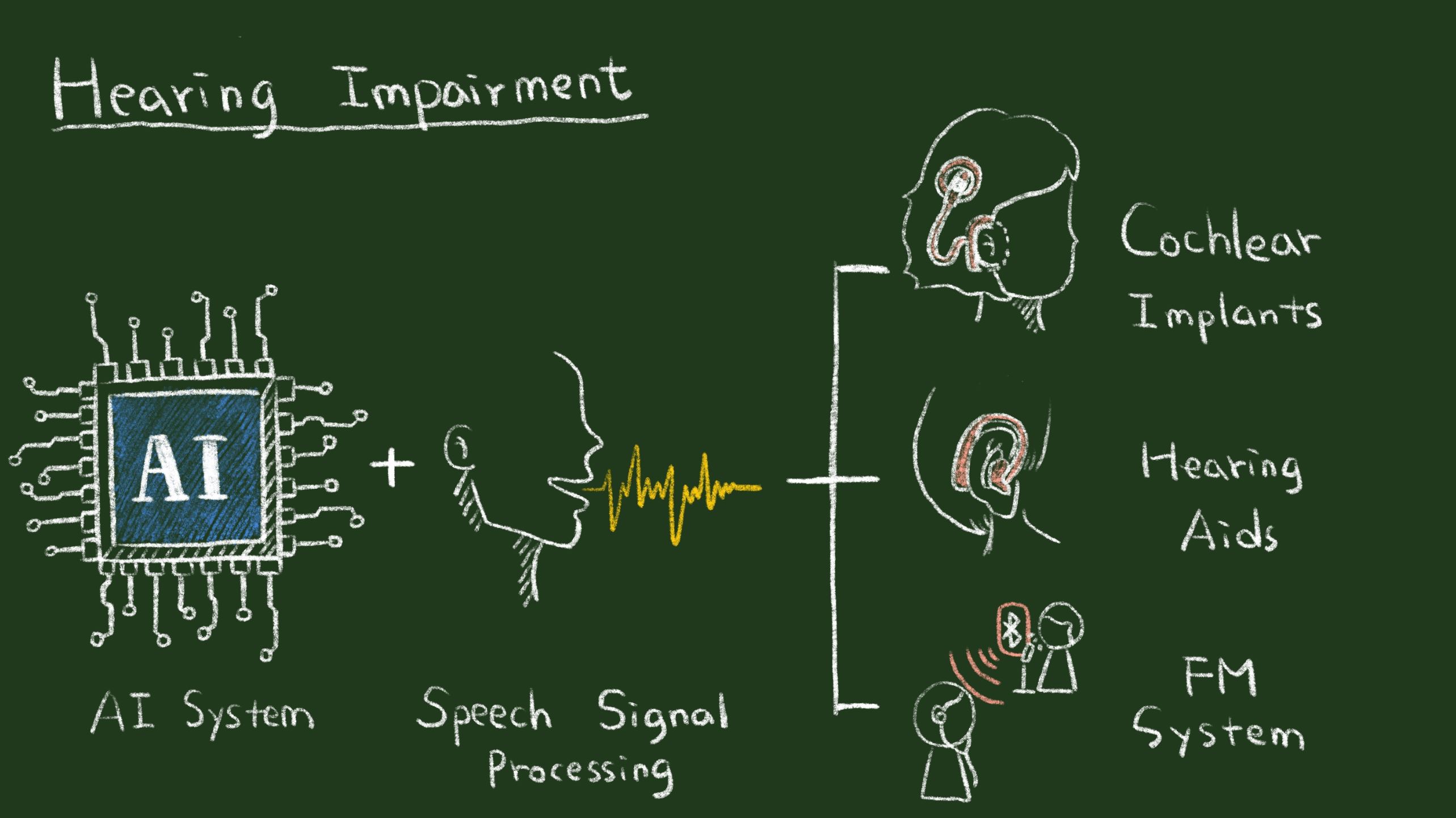
| 產業應用性 | 近年來由於高齡人口比率持續升高以及青少年濫用隨身音響設備的情形加劇,進而導致聽力受損或喪失之人口逐漸增多。為因應此現象,聽覺輔具的研究成為近日全球矚目的前瞻性課題。曹昱博士開發出的除噪演算法可以應用於聽覺輔具(人工電子耳、助聽器、輔聽器、集音器等),對國內聲學相關產業做出更多實質的貢獻。 |
||
| 關鍵字 | 語音增強系統 深度學習 語音理解度 端到端的時域語音增強系統 聽覺輔具 語音理解度 語音辨識 人工電子耳 助聽器 語音調頻系統 | ||
| 備註 | 基於這部分的研究成果,我們在國際知名研討會 APSIPA 2019 以及 Interspeech 2020 發表Tutorial Lectures,內容如下: |
||
- 聯絡人
- 曹昱
- 電子信箱
- yu.tsao@citi.sinica.edu.tw
其他人也看了