



| 技術名稱 | 低功耗高性能AI神經網路之設計、加速及佈署 | ||
|---|---|---|---|
| 計畫單位 | 國立陽明交通大學 | ||
| 計畫主持人 | 林永隆 | ||
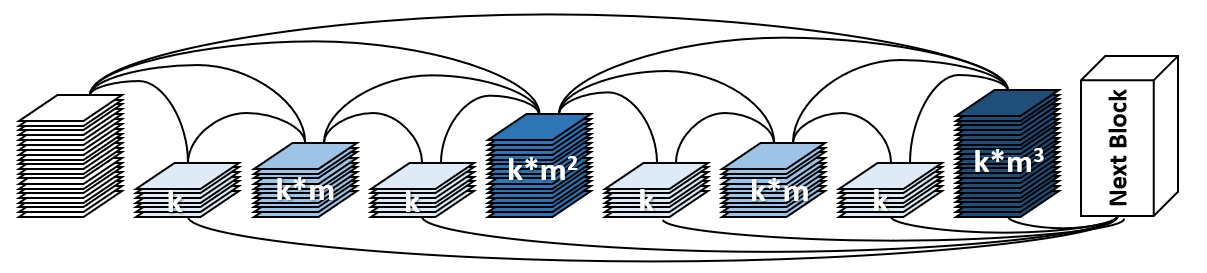
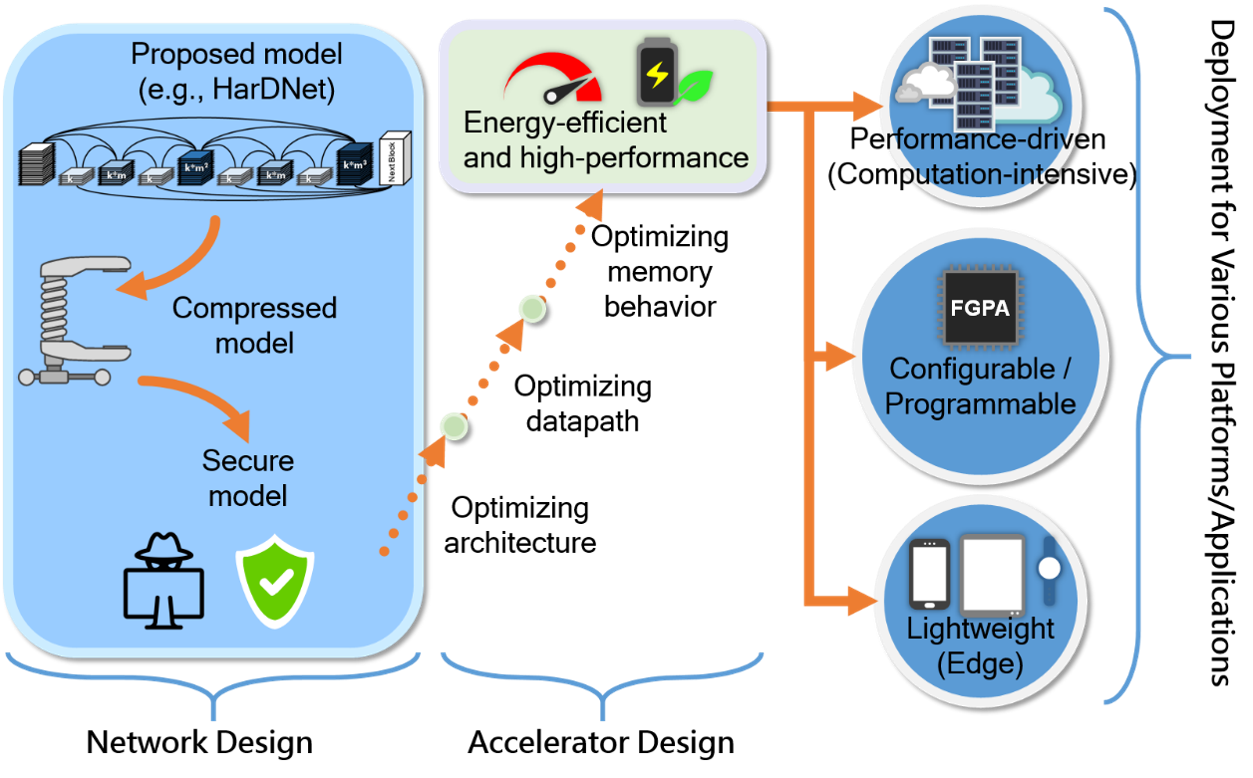
| 技術簡介 | 本團隊將基於LPCVC 2020的競賽成果以及ICCV 2019的神經網路骨幹架構,做多項的技術展示,包括Deployment of HarDNet on GPU (功耗:大於200瓦), FPGA (數十瓦), Raspberry PiGoogle Coral TPU (小於10瓦)。 |
||
| 技術影片 |
|
||
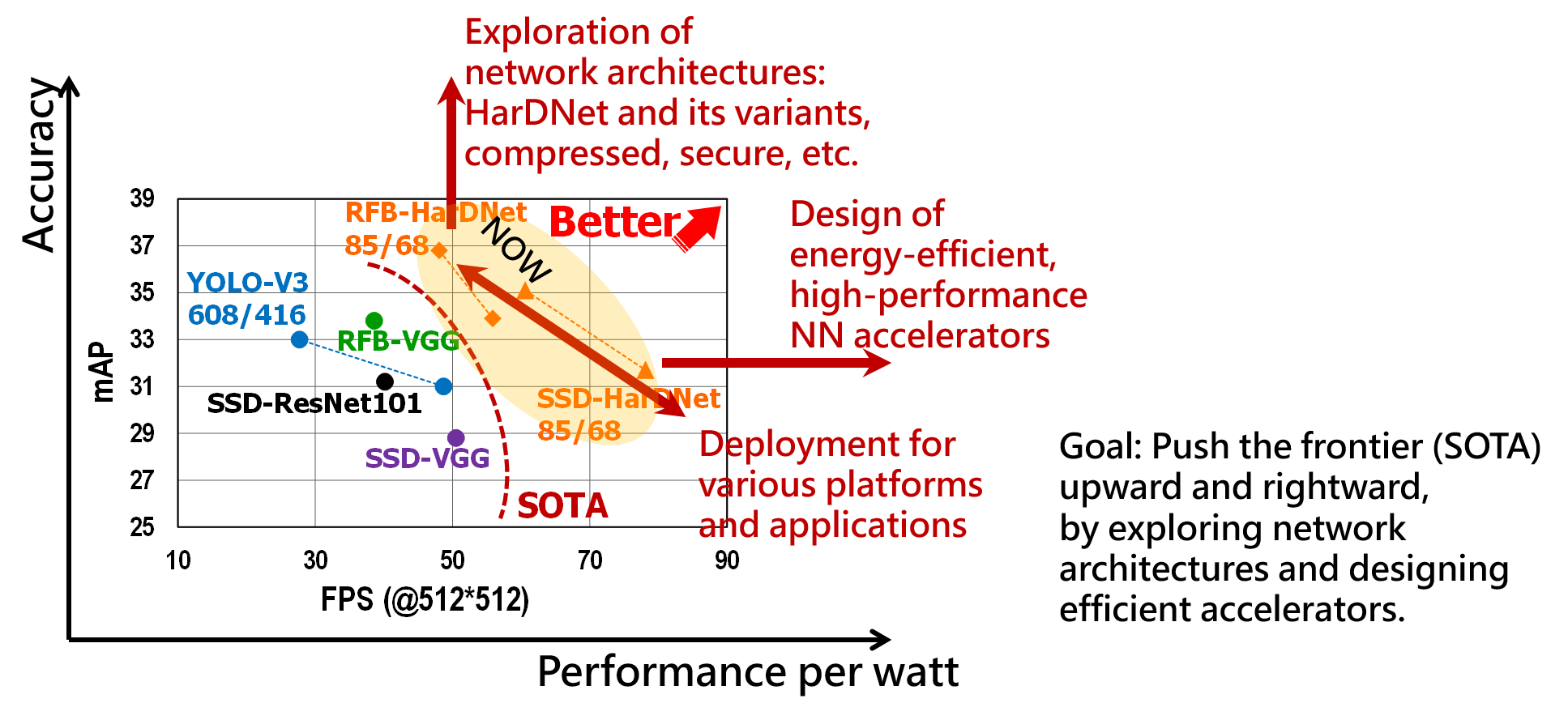
| 科學突破性 | 運行在各式的平台如GPU、FPGA、AI edge device上,HarDNet的整體性能(速度、準度)皆具有高度的競爭力,尤其在semantic segmentation這個應用上,被Papers with Code網站評比為世界第一,獲得state of the art (SOTA)的殊榮。 |
||
| 產業應用性 | "1. 矽谷智慧語音晶片大廠採用本團隊開發之RNN加速方案,其高階AI語音晶片已於2020下線,該晶片預估產值上看億元美金。_x000D_ 2. 台灣記憶體晶片製造大廠與本團隊共同合作AI computing in memory技術,開創下一代晶片新藍海。_x000D_ 3. 成立新創公司,為產業提 |
||
| 媒合需求 | 天使投資人、策略合作夥伴 |
||
| 關鍵字 | HarDNet (Harmonic DenseNet) 神經網路架構 硬體加速器 終端AI之佈署 模型壓縮 神經網路之安全性 近似計算 | ||
- 聯絡人
- 黃鈺雯
- 電子信箱
- patty@cs.nthu.edu.tw
其他人也看了