



| 技術名稱 | 深度自然語言處理與學習技術 | ||
|---|---|---|---|
| 計畫單位 | 國立交通大學 | ||
| 計畫主持人 | 簡仁宗 | ||
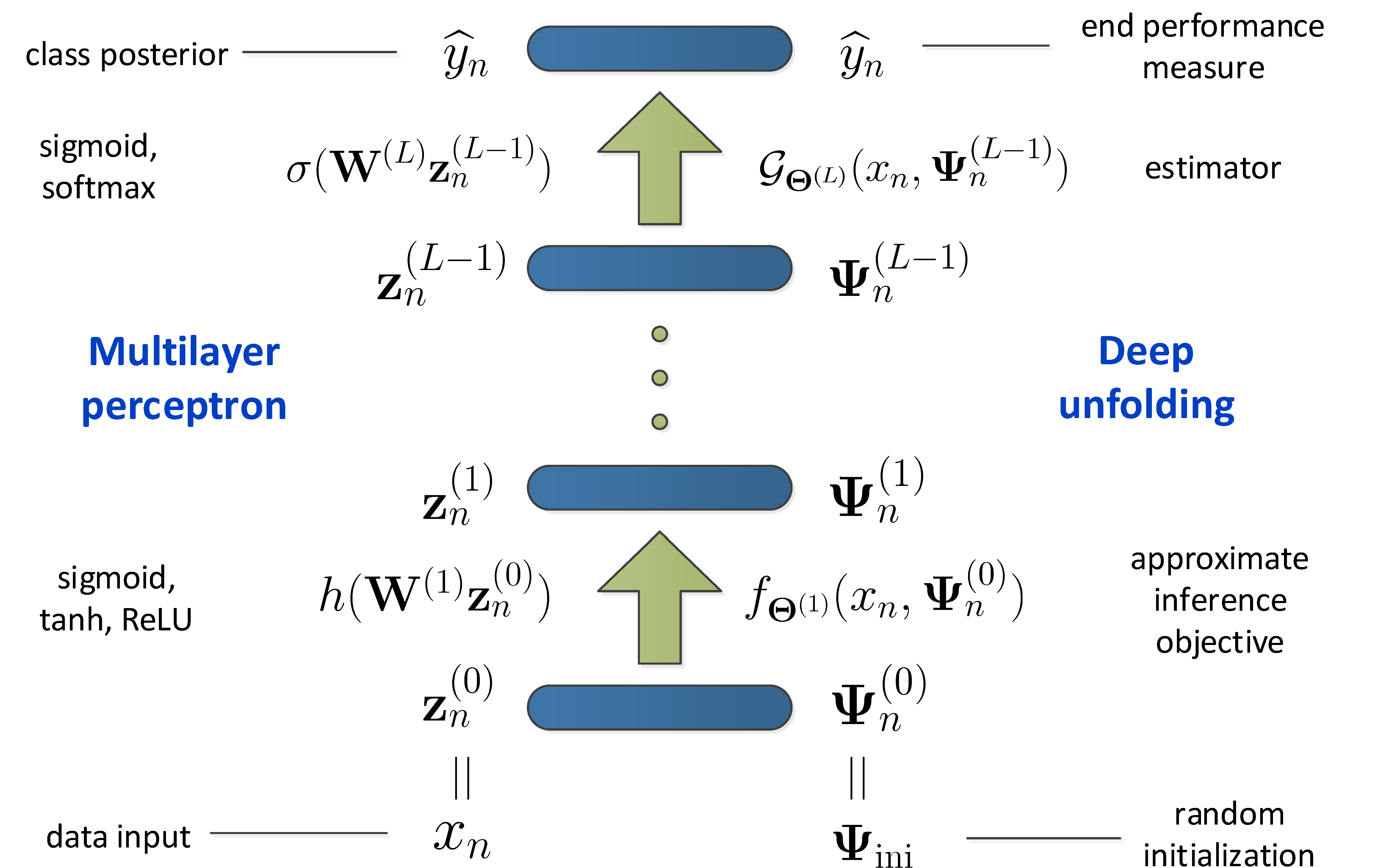
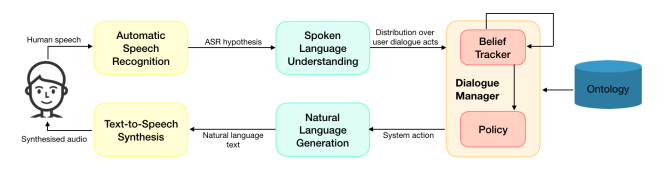
| 技術簡介 | 機器學習與深度學習近年來爆炸性的發展,促使人工智慧獲得巨大的成功。尤其是在網際網路時代下,大量數據快速累積,機器不僅要能理解各式異質化的資訊內容與自然語言,更要能延伸做出自動分類、回覆甚至預測等功能。這類創新技術可以具體實現在多元產業應用中並帶來龐大的產業機會,例如一般民眾熟悉的語音助理、搜尋引擎、智慧問答、語音辨識到機器翻譯等。透過科技創新為產業賦予高附加價值,實現深度學習與語意理解以提供廣泛客製化方案,建立高智慧之自然語言理解系統。然而,異質性環境下收集到的巨量自然語音或文句資料充滿了多樣性與複雜性,造成自然語言模型建立的困難,因此需要建立強大的統計分析與深度學習模型,透過反覆調整神經網路的參數和架構,不間斷執行深度學習並達成強大自然語言理解能力。 |
||
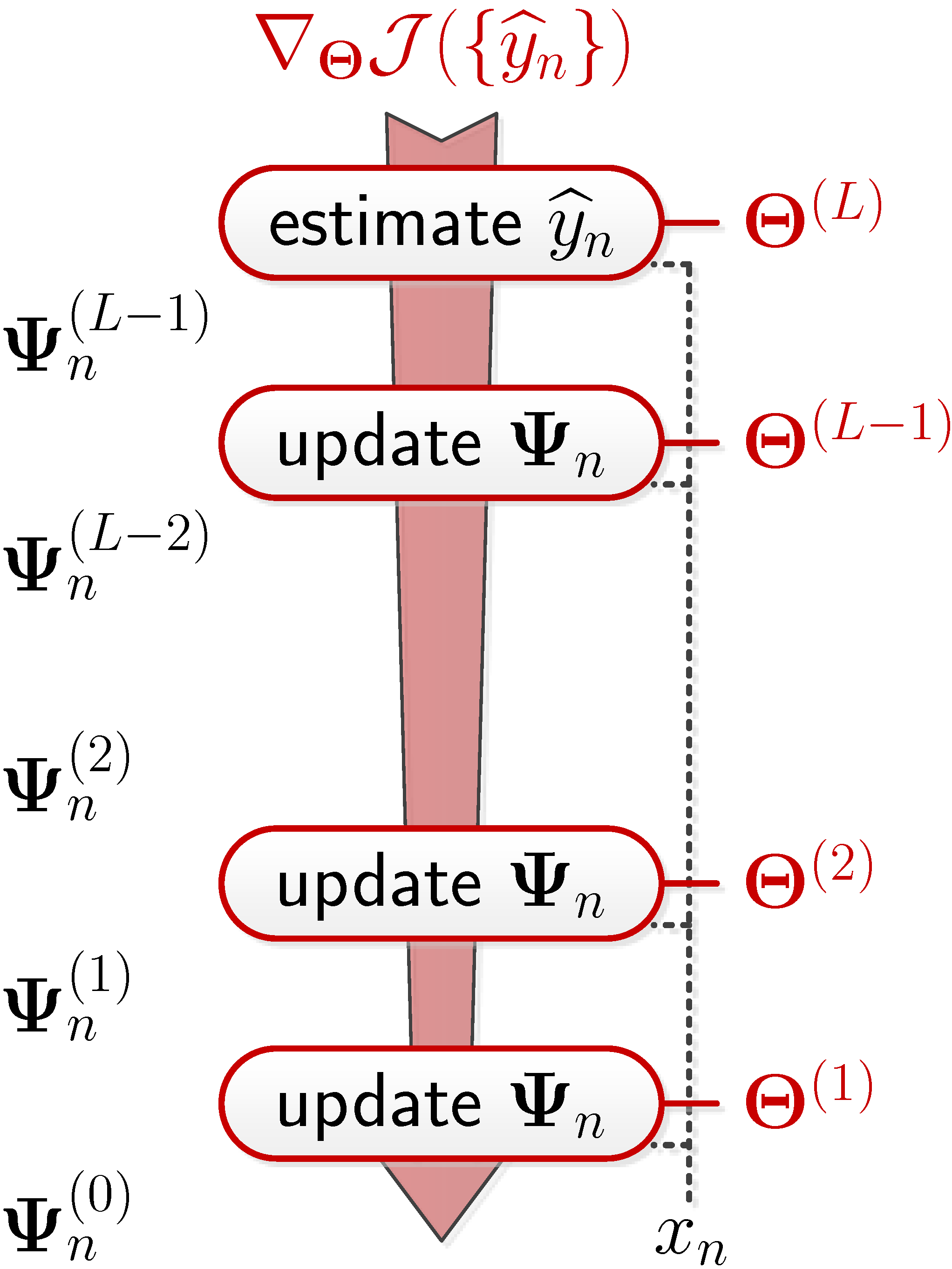
| 科學突破性 | 隨機時間差異在強化式學習中可於視頻遊戲中訓練出圖像在時間域之預測能力,亦可在自然語言表達上學習出多重字詞在文本上的長距離關係,再利用新型深層轉換器理解字詞本身含意及背後語意找尋出字詞間的關聯,並且利用量化神經網路將深層模型壓縮在使用者端,適應性調整量化等分及非對稱量化準則能更充分表達資料的真實特性。 |
||
| 產業應用性 | 本技術建立統計式神經網路模型並進行序列型深度學習,應用場域極為廣泛,舉凡推薦商品、智慧問答、文件排名、自動摘要、文件分類都會應用到這項技術,然而在大多數自然語言任務上,機器模型需要學習不同情境上的文字意義,我們開發出深層神經網路模型之壓縮技術,已有效節省記憶體區需求空間並達成有簡潔精準的深層模型。 |
||
| 關鍵字 | 人工智慧 機器學習 深度學習 自然語言處理 語音辨識 語意理解 智慧代理人 對話系統 問答系統 多媒體資訊系統 | ||
- 聯絡人
- 簡仁宗
- 電子信箱
- jtchien@nctu.edu.tw
其他人也看了