



| 技術名稱 | 一個偵測HTTP服務新形態異常的新穎方法 | ||
|---|---|---|---|
| 計畫單位 | 國立中興大學 | ||
| 計畫主持人 | 廖宜恩 | ||
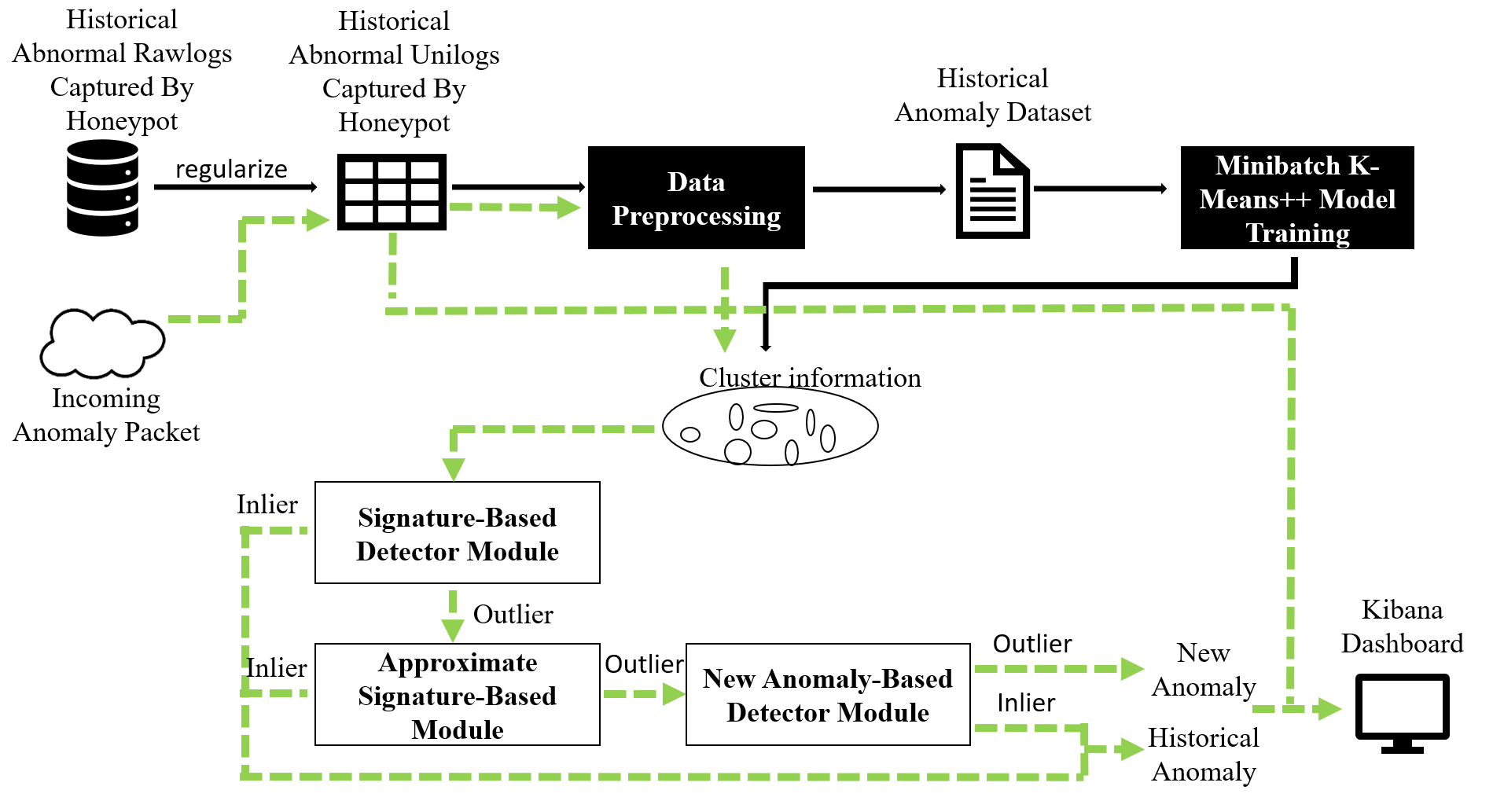
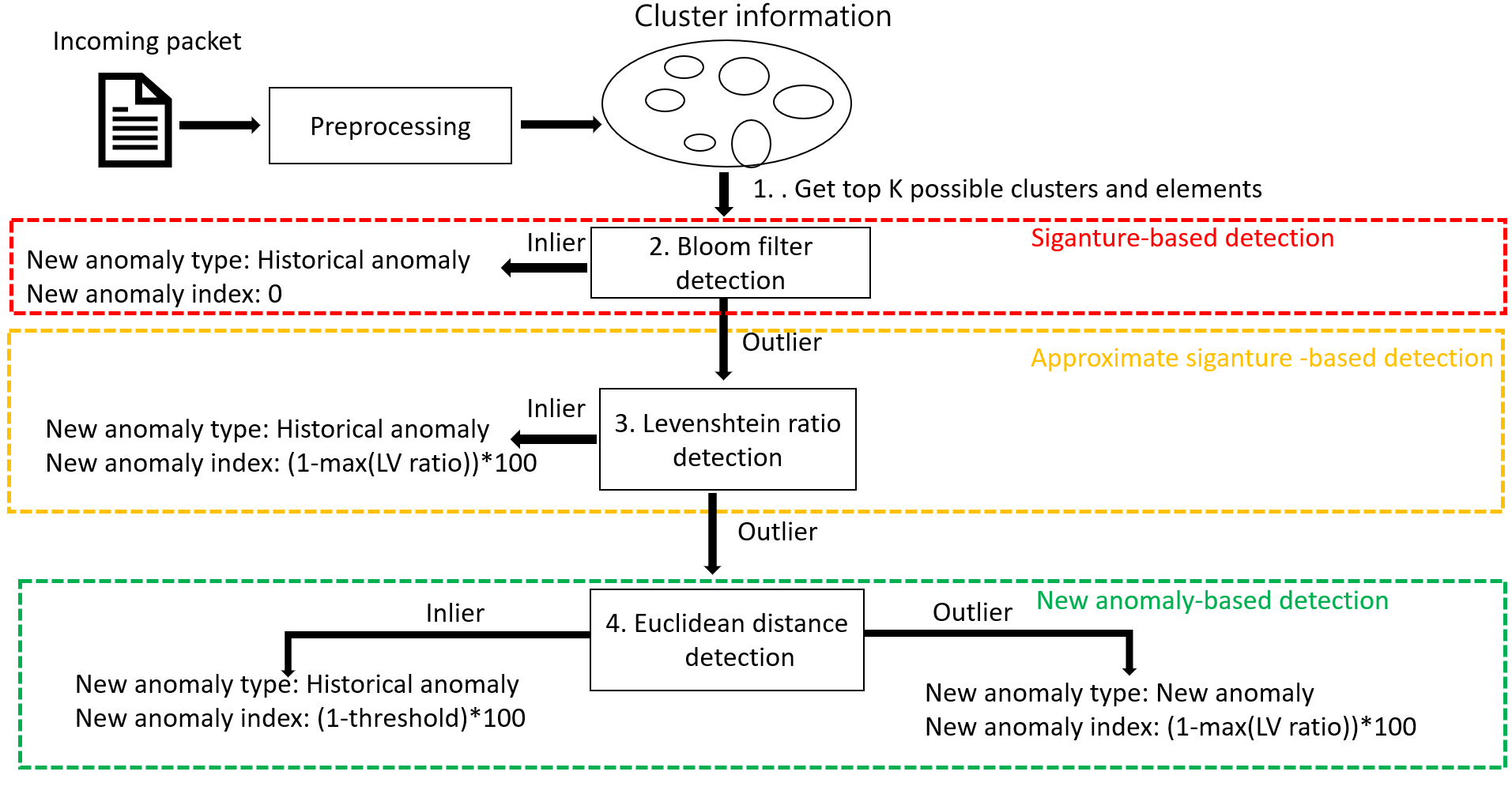
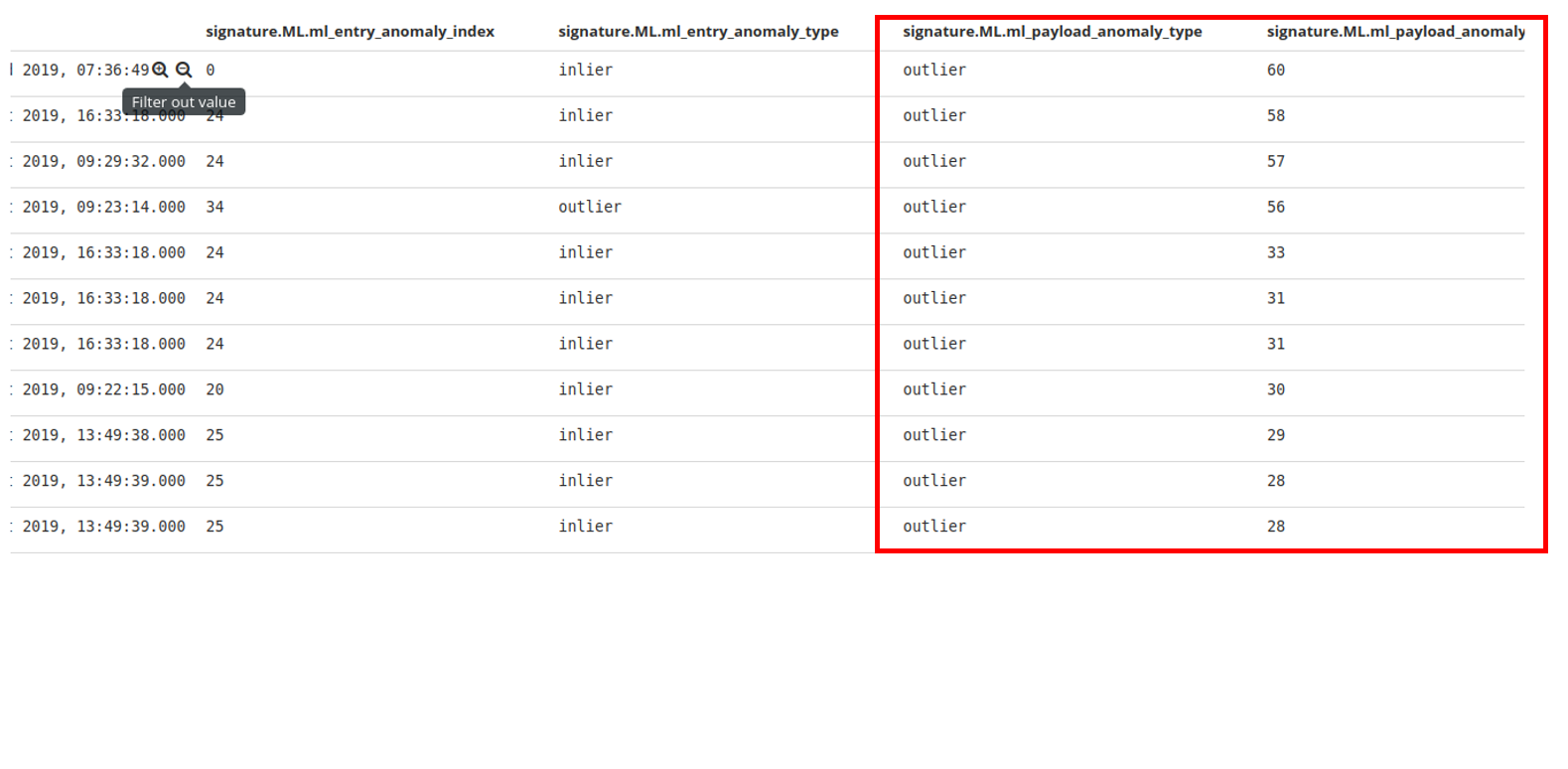
| 技術簡介 | 本方法(簡稱DNA of HTTP)能夠針對Glastopf蜜罐新捕獲的異常HTTP服務流量,辨別其異常型態是否於過去歷史捕獲的異常流量中出現過,幫助分析人員能夠從海量的蜜罐捕獲流量中,自動且快速提取具有高研究價值的新型態異常,降低分析過程所需投入時間成本。透過半監督的方式學習蜜罐捕獲的歷史異常流量其行為模式,並以基於特徵、近似特徵、新的異常的偵測方式,識別新捕獲異常流量是否為新型態異常。本方法能夠廣泛應用於許多資訊安全機構,協助分析人員檢視所部署蜜罐捕獲之異常流量。 |
||
| 科學突破性 | 整體而言,本系統結合了基於特徵、近似特徵、異常的偵測方法優勢,能夠對擁有模式複雜、無標籤且十分不平衡的蜜罐捕獲異常流量進行良好的學習,並準確且有效率的快速辨認出新型態異常流量,降低人員所需檢閱log之時間。 |
||
| 產業應用性 | 本系統針對資訊安全研究機構部署之蜜網,建立半監督式新型態異常偵測系統,能夠自動快速辨認蜜罐捕獲的大量流量是否為新型態異常,並給予新型態異常指數,以大幅降低分析人員所需檢視log的數量與所需花費的時間,使其能夠快速的檢視真正具有高度研究價值的新型態異常。 |
||
| 關鍵字 | 新型態異常偵測系統 入侵偵測系統 異常偵測 蜜罐 工業控制系統 HTTP 半間督式學習 基於特徵 基於近似特徵 基於異常 | ||
- 聯絡人
- 高子棋
- 電子信箱
- brucewarm26@gmail.com
其他人也看了